What is an Interrupt
Interrupt is an event that changes the program flow i.e. the instruction stream being executed by the CPU. Interrupts are also generated by various devices connected to the CPU or they caused by bugs within the software. Interrupts are way for hardware to signal to the processor.
Interrupts and Exceptions
- Exceptions Synchronous Interrupts:
Caused by software and produced by control unit of CPU.
Example: A bug in software or a page fault. Kernel handles these exceptions by following the steps defined (in kernel code) to recover from such a condition.
- Interrupts Asynchronous Interrupts:
Caused by hardware devices.
Example: Keypress/mouse movement by user.
Interesting Points about Interrupts
- Interrupts are asynchronous and they are nested.
- An interrupt can occur while kernel is handling another interrupt. When kernel is executing some critical region, interrupts are disabled and kept the critical region as small as possible.
- By disabling interrupts, Kernel guarantees that an interrupt handler will not preempt the critical code.
- The interrupts and exceptions are identified by a number between 0 to 255.
- The code executed by interrupt handler is not a process switch, rather its ran at an expense of the process that was running when interrupt was received.
- Interrupt handling is critical for Kernel but since handling can take long time in the case of slow I/O devices. Hence the interrupt handling is divided into two parts
- Urgent: Kernel executes this right away.
- Bottom Halves: Deferred to execute later. (using various techniques like soft irqs, Tasklets, Task/ Work Queues)
Classification of Interrupts
- Maskable
- These are interrupt requests issued by I/O devices.
- There are two states for a maskable interrupt.
- The vectors of maskable interrupts are altered by programming the interrupt control.
- Nonmaskable
- They are always recognized by CPU.
- The vectors of non-maskable interrupts are fixed.
Classification of Exceptions
- Processor Detected
- CPU detects an anomalous condition while executing an instruction
- Faults:
- Example: Page faults
- Faults can be corrected and once corrected, program can be resumed.
- Traps:
- They can be reported immediately at the next instruction.
- Used mainly for debugging.
- Aborts:
- These are severe errors like hardware failure
- The process is terminated on receiving this signal.
- Programmable Exceptions:
- Often called as software interrupts.
- Used to implement system calls and debugging.
| Exception Number |
Explanation |
Type |
| 0 |
divide by zero error |
Fault |
| 1 |
Debug |
Trap or Fault |
| 2 |
Not Used |
|
| 3 |
Breakpoint |
Trap |
| 4 |
Overflow |
Trap |
| 5 |
Bounds check |
Fault |
| 6 |
Invalid opcode |
Fault |
| 7 |
Device not available |
Fault |
| 8 |
Double Fault |
Fault |
| 9 |
Coprocessor segment overrun |
Abort |
| 10 |
Invalid TSS |
Fault |
| 11 |
Segment not present |
Fault |
| 12 |
Stack segment fault |
Fault |
| 13 |
General protection |
Fault |
| 14 |
Page Fault |
Fault |
| 15 |
Reserved by Intel |
|
| 16 |
Floating-point error |
Fault |
| 17 |
Alignment check |
Fault |
| 18 |
Machine check |
abort |
| 19 |
SIMD floating point exception |
Fault |
_Page Fault occurs when the process try to address a page in its address space but is not currently in RAM. When Kernel is handling this exception, it may suspend current process and switch to another process until the page is available in the RAM. The process switch is done because of high latency of RAM (200 ns or serveral hundred CPU cycles). _
Hardware for Interrupt Handling
- Each hardware device connected to a computer has a single output line named as Interrupt Request (IRQ) line.
- There is a hardware circuit called Programmable Interrupt Controller (PIC) to which all the IRQ lines are connected.
- Interrupt Controller (PIC) monitors IRQ lines for raised signals.
- In case of multiple signals raised simultenously, the signal with lower pine number is selected.
- When there is a signal raised, its stored in signal vector, then the vector is sent to CPU and signal is raised to CPUs INTR pin to wait until the CPU acknowledges the signal.

Image credit: By Jfmantis – Own work, CC BY-SA 3.0, https://commons.wikimedia.org/w/index.php?curid=18168230
APIC – Advanced Programmable Interrupt Controller
In modern multiprocessor systems, there is a local APIC chip per CPU. The APIC has following components:
- 32 bit registers
- Internal clocks
- Local timer device
- Two additional lines LINT 0 and LINT 1
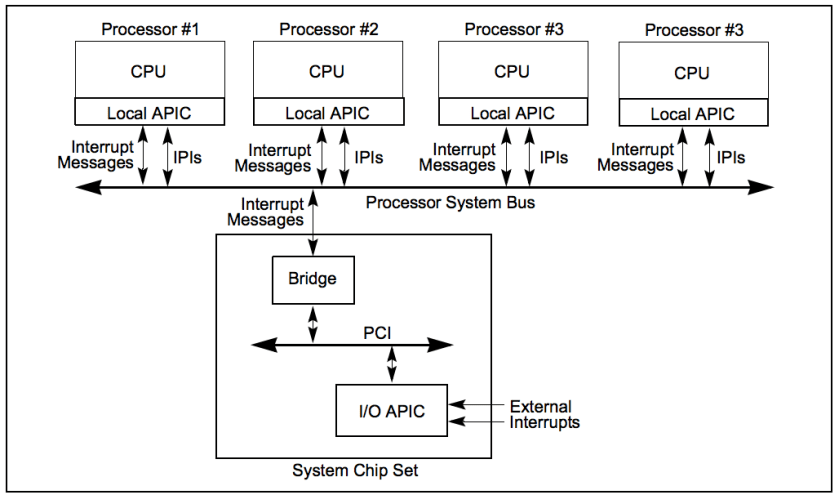
Image credit: [Intel Software Developer manual vol 3.](https://www.intel.com/content/dam/www/public/us/en/documents/manuals/64-ia-32-architectures-software-developer-vol-3a-part-1-manual.pdf)
Categories of Interrupts
- I/O Interrupts
- Timer Interrupts
- Interprocessor interrupts
Types of Actions taken by Linux on interrupts
- Critical
- Critical actions are executed within the interrupt handler immediately.
- Noncritical
- These are quick to finish and hence executed by interrupt handler immediately.
- Noncritical deferrable
- These may be delayed for a long time interval without affecting the kernel operations
IRQ Distribution in Multiprocessor System
The kernel tries to distribute the IRQ signals coming from the hardware devices in a round-robin fashion among all the CPUs.
The interrupts coming from external hardware can be distributed within CPUs in following ways
- Static Distribution
- Dynamic Distribution
IRQ affinity
The kernel provides a functionality to redirect all the interrupts to a particular CPU. This is achieved by modifying Interrupt Redirection Table entries of the I/O APIC. IRQ affinity of particular interrupts can also be changed by writing a new CPU bitmap mask into the /proc/irq/n/smp_affinity file.
Interrupt Handling
When an interrupt is received, kernel runs inyerrupt handler or interrupt service routine code. These are ‘C’ functions. A data structure named Interrupt Descriptor Table (IDT) stores each interrupt or exception vector with the address of the corresponding interrupt or exception handler. That Table must be properly initialized before the kernel enables interrupts.
Top Halves vs Bottom Halves
- Interrupt handling should be fast but there may be large amount of work involved, hence the handling is divided into two parts:
- Top Half: Executed immediately and perform time critical work like acknoledging the interrupt.
- Bottom Half: This part can be deferred like communicating with I/O.
Deferred Part of Interrupt Handling
- As stated above the interrupt handling has two parts: critial and non critical (deferred handling).
- SoftIRQs, Tasklets, WorkQueues etc are ways to process deferred part of interrupt handling which is also called as bottom halves.
| SoftIRQs |
Tasklets |
| They are statically allocated. |
can also be allocated and initialized at runtime |
| softirqs are reentrant functions and must explicitly protect their data structures with spin lock |
Do not need synchronization because Kernel handles that for them. |
| provide the least serialization |
Tasklets of the same type are always serialized: in other words, the same type of tasklet cannot be executed by two CPUs at the same time |
|
Easy to code |
Work Queues
- They defer work into Kernel Queue.
- Functions in work queues run in process context and hence the function can be blocking functions or can sleep.
- Function in a work queue is executed by a kernel thread, so there is no User Mode address space to access.
Exception Handling
- The exceptions raised by CPU are handled by linux as error conditions.
- Kernel sends a signal to the process about the erroneous condition.
- Steps taken to handle exception:
- Save registers to Kernel Stack
- Invoke C-level function to handle exception.
- call ret_from_exception() function and exit!
Signals
Signals are software generated interrupts. A signal is generated for a process (or sent to a process) when the event that causes the signal occurs. When the signal is generated, the kernel usually sets a flag of some form in the process table. A signal is delivered to a process when the action for a signal is taken. Between the time of generation and delivery, the signal is pending.
When a process receives a signal, it can do either of following.
- Ignore: except for
SIGKILL and SIGSTOP all signals can ignored.
- catch the signal: call some callback on receiving this signal. Again,
SIGKILL and SIGSTOP can not be caught or blocked.
- Apply some default action.
On Termination of the process the memory image of the file is stored in the pwd of the process.
Reentrant functions: functions that are guaranteed to be safe to call from within a signal handler. These functions are async-safe functions meaning they block the signals before entering into a critical region