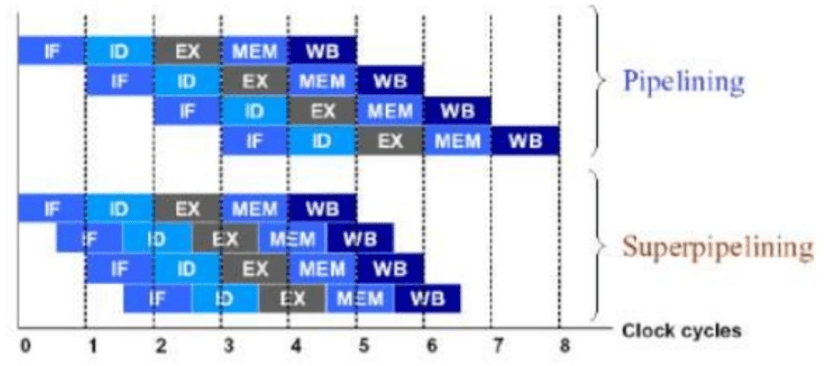
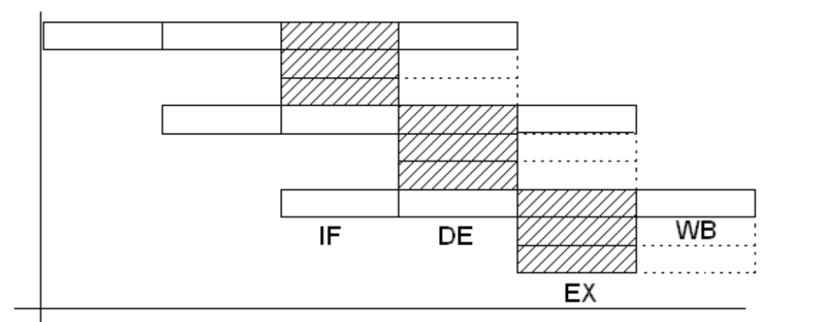
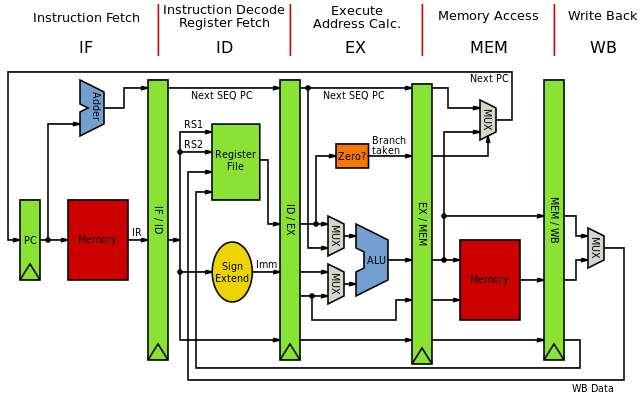
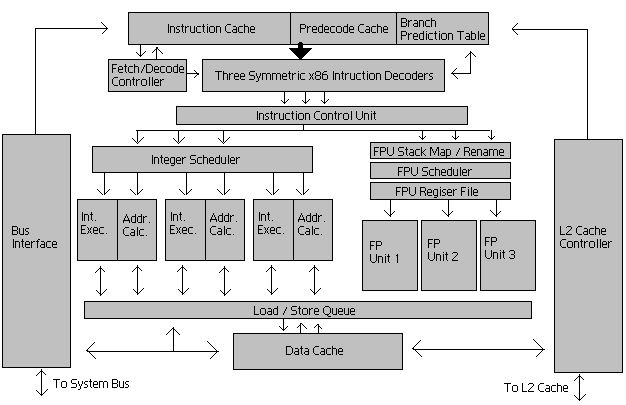
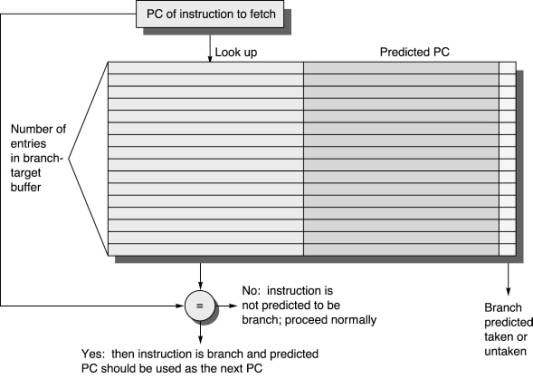
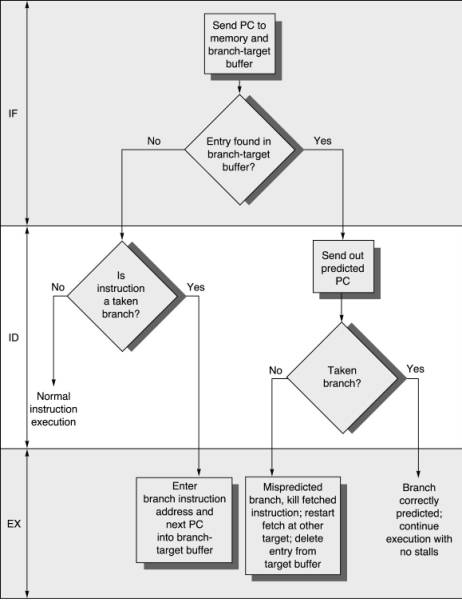
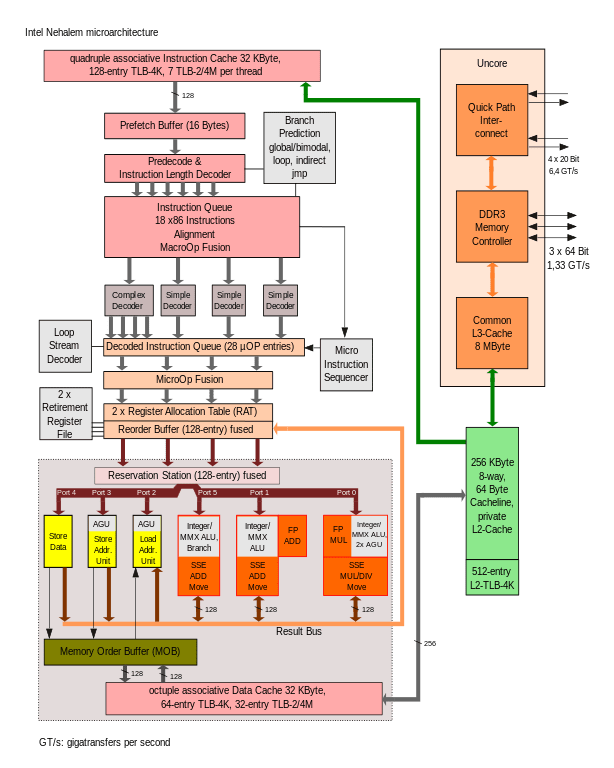
The modern microprocessors have a speed of 3GHz vs the main memory (RAM) has a speed of 133 MHz. With the newest advancements in hardware, the memory bandwidth only increased between DDR to DDR2 and DDR3 but the latency decrease by a very little factor. Caches were introduced as a level of indirection in order to hide the latency gap. Caches work on two very important principles of data access patterns:
- Spatial Locality: if a memory location is accessed, the nearby memory location is most probably accessed, example: arrays
- Temporal Locality: if memory location is accessed, there is probability that the same location will be accessed again, example: loops
Modern x86 processors have the hierarchy of an L1, L2 and a distributed LLC accessed via the on-die scalable ring architecture. L1 and L2 cache are private to the core and the LLC is shared within all the cores.
- The Access Timing in terms of CPU cycles
- L1 – 4 cycles
- L2 – 12 cycles
-
LLC – 26 to 31 cycles
- The cache size
- L1 32 KB data cache (L1I) + 32 KB instruction cache (L1D)
-
L2 – 256 KB
- LLC – 8 MB to 56 MB.
- Cache line
- It is unit of transport between memory.
- on x86 the cache line size is 64 bytes
- Data Prefetchers
-
spatial prefetcher attempts to complete every cache line fetched to the L2 cache with another cache line to fill a 128-byte aligned chunk.
-
streamer prefetcher monitors read requests from the L1D cache and fetches the appropriate data and instructions. Server vendors might use their own designation for L1 and L2 prefetchers
-
- Cache Snooping protocols:
CACHE STATE
DEFINITION
STATE DEFINITION
CACHE LINE EXISTS IN
M
Modified
The cache line is updated relative to memory
Single core
E
Exclusive
The cache line is consistent with memory
Single core
S
Shared
The cache line is shared with other cores. (The cache line is consistent with other cores, but may not be consistent with memory)
Multiple cores
I
Invalid
The cache line is not present in this core L1 or L2
Multiple cores
Types of Caches
- Directly mapped caches:
- an address can reside only at a particular address in cache.

- Direct mapping is simple and inexpensive to implement, but if a program accesses 2 blocks that map to the same line repeatedly, the cache begins to thrash back and forth reloading the line over and over again meaning misses are very high.
- Processor registers use logic as direct mapped.
- Fully associative caches
- any block can go into any line of the cache.
- Set-associative caches
- set associative addresses the problem of possible thrashing in the direct mapping method. It does this by saying that instead of having exactly one line that a block can map to in the cache, we will group a few lines together creating a set. Then a block in memory can map to any one of the lines of a specific set. There is still only one set that the block can map to.

Cache Eviction Policy
There are many algorithms for cache eviction in case of conflict example:
- FIFO – First in first out
- keep track of insertion time and evicts block that is oldest.
- LRU – least recently used
- keep track of references to the data in cache and data with lowest references will be evicted
- Random
Cache Flush Policy
When the data is updated in cache, there are following policies for updating main memory with updates to cache. Since the main memory is slow, the update is deferred as much as possible.
- Write-through:
- Cache pushes all the changes to the main memory immediately
- advantages are the implementation is simple and less error prone.
- disadvantages are requirement of bandwidth because of subsequence writes and also write backs take latency because of slowness of main memory.
- write-no-allocate:
- the block is modified in the main memory and not loaded into the cache.
- write-allocate:
- the block is loaded on a write miss, followed by the write-hit action.
- Write back:
- the update is deferred as much as possible.
Cache Misses
- Cold or compulsory misses:
- Cache misses because of first reference to the block in program
- Capacity misses:
- Cache misses because of capacity is not enough.
- Conflict misses:
- Cache misses because of conflicting cache location.
- Coherent misses:
- The coherence miss count is the number of memory accesses that miss because a cache line that would otherwise be present in the thread’s cache has been invalidated by a write from another thread.
- Coverage misses:
- he coverage miss count is the number of memory accesses that miss because a cache line that would otherwise be present in the processor’s cache has been invalidated as a consequence of a directory eviction.
Cache Hierarchy
Image credit: http://www.1024cores.net/home/parallel-computing/cache-oblivious-algorithms?

Translation Lookaside Buffer – TLB
- The TLB is an other form of cache that stores the virtual to physical mappings of addresses.
- TLB is fully associative.
- There are generally 2 levels of TLB and less number of entires (128).
- When a page fault occurs, the hardware starts address translation. Since the address translation in x86 is 5 level, the hardware start looking into the TLB if the address has been translated recently and if found, the translation returns immediately.
- If the address is not found in the TLB, the hardware walks through the page tables entries in the main memory in order to find the physical address for that page.