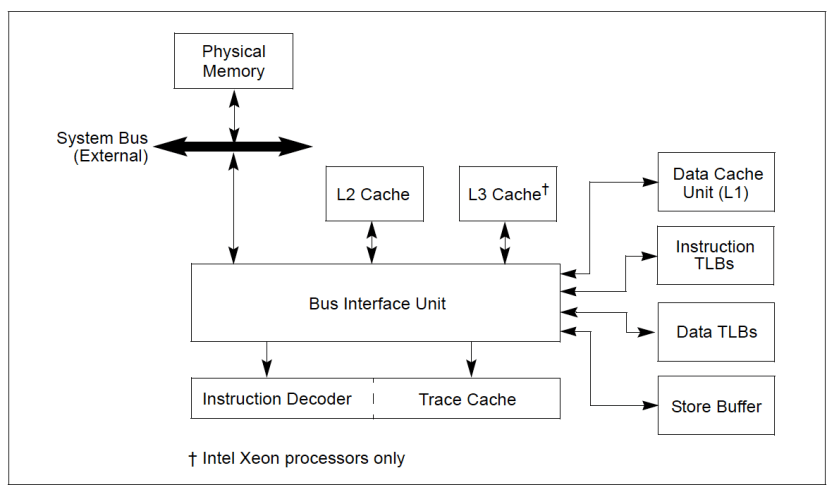
A process is a program in execution. Since linux represent everything in terms of files, currently running processes are also represented using /proc file system. The proc/<pid> contains open files (sockets), pending signals, process state, kernel data structures, threads of execution and data section.
Processes provides two types of virtualization
- Virtual Processor
- Virtual Memory
Processes are created on linux using fork() system call. When fork() is called, a process is created which is child of process who is called fork(). The reason it’s called as a child because it gets copy of resources (data, variables, code, pages, sockets etc) from it’s parent process.
The list of processes are stored in a doubly linked list called as task list. The process descriptor is type struct task_struct defined in <linux/sched.h> .
Processes are identified by PID. PID is a defined by pid_t data structure which is an integer up to 32,768. Generally processes up to number 1024 is kernel processes and rest of them are user processes. When a new process is forked, the number is not sequential but its randomized in order to avoid being guesses. When number is processes reaches max limit, the number is reseted and starts from 1024. The limit of number of processes can be increased by setting value at proc/sys/kernel/pid_max.
Process creation
-
fork()
- a process can create another process using fork() function.
- It is implemented using clone()
- fork(), vfork() and __clone() calls clone() which calls do_fork() which calls copy_process()
- the process created is called as child process
- Example of simple fork call:
pid_t pid = fork();
- if return value of fork() call is 0, fork is successful and control block is in child process.
if (pid == 0)
{
printf("child process");
}
- if return value of fork() call is greater than 0, fork is successful and control block is in parent process process.
else if (pid > 0)
{
printf("parent process");
}
- if return value of fork() is negative, the call is failed.
else
{
printf("fork failed");
}
- fork() creates a child process that is a copy of the current task. It differs from the parent only in its PID, its PPID (parent’s PID), and certain resources and statistics (e.g. pending signals) which are not inherited
- Besides the open files, other properties of the parent are inherited by the child:
- Real user ID, real group ID, effective user ID, and effective group ID
- Supplementary group IDs
- Process group ID
- Session ID
- Controlling terminal
- The set-user-ID and set-group-ID flags
- Current working directory
- Root directory
- File mode creation mask
- Signal mask and dispositions
- The close-on-exec flag for any open file descriptors
- Environment
- Attached shared memory segments
- Memory mappings
- Resource limits
-
exec():
- The
exec() family of function calls creates a new address space and loads a new program into the newborn child immediately after a fork.
- There are following variations of exec calls
-
int execl(const char *path, const char *arg, ...
/* (char *) NULL */);
-
int execlp(const char *file, const char *arg, ...
/* (char *) NULL */);
-
int execle(const char *path, const char *arg, ...
/*, (char *) NULL, char * const envp[] */);
-
int execv(const char *path, char *const argv[]);
-
int execvp(const char *file, char *const argv[]);
-
int execvpe(const char *file, char *const argv[],
char *const envp[]);
| Function |
pathname |
filename |
fd |
Arg list |
argv[] |
environ |
envp[] |
|
execl |
* |
|
|
* |
|
* |
|
|
execlp |
|
* |
|
* |
|
* |
|
|
execle |
* |
|
|
* |
|
|
* |
|
execv |
* |
|
|
|
* |
* |
|
|
execvp |
|
* |
|
|
* |
* |
|
|
execve |
* |
|
|
|
* |
|
* |
|
fexecve |
|
|
* |
|
* |
|
* |
|
| (letter in name) |
|
p |
f |
l |
v |
|
e |
|
Process 0 and 1
Process 0 is ancestor of all processes which is also known as swapper process. This process is build from scratch during boot up. Process 0 initializes all the data structures needed by kernel, enables interrupts, and creates init process which is process 1.init process, invoked by the kernel at the end of the bootstrap procedure. It is responsible for bringing up the system after the kernel has been bootstrapped. init usually reads the system-dependent initialization files (/etc/rc* files or /etc/inittab and the files in /etc/init.d) and brings the system to a certain state. Process 1 never dies. It is a normal user process, not a system process within the kernel, but runs with superuser privileges.
State of a Process
Process can be any one of following states:
- TASK_RUNNING
- Process is being executed on CPU or waiting
- TASK_INTERRUPTABLE
- Process is sleeping/suspended.
- TASK_UNINTERRUPTABLE
- Process is in sleeping state but signal to these processes will not change state of the process.
- TASK_STOPPED
- TASK_TRACED
- Process is being debugged
- EXIT_DEAD
- Child process is being removed because parent process issued wait4() or waitpid()
- EXIT_ZOMBIE
- Child process being terminated but parent has not issued wait() or waitpid()
Copy on Write – an optimization on fork()
All the data and resources that belong to the parent are not copied to child. This is done is steps and as needed. This is an optimization in order to delay copying data as needed. The another reason is in calls such as exec(), none of the parent data is actually needed, there should not be a need to copy any pages from parent.
Process Switch
During process switch the registers are saved in kernel memory area for process and loaded back when process resumes on CPU. This is was done using far jmp assembly instruction on x86. On linux 2.6 onwards software is used for context switching instead of hardware context switching. Software context switch is safer and faster.
Scheduling
Processes work on time slicing basis giving user the illusion that only the user has access to the CPU and the memory is unlimited. The scheduling of processes depend upon scheduling policy or algorithm. The scheduling algorithm must schedule in such a way that processes should have fast response, good throughput, limited use of resources and honor the priorities.
Linux processes are preemptive. A process with high priority than low priority runs first by interruption of low priority process is one is running. There are following classes of Linux processes:
- SCHED_FIFO
- SCHED_RR
- SCHED_NORMAL
Scheduling factors for a process
- static priority: between 100 (high priority) to 139 (low priority)
- nice value: -20 (high priority) to 19 (low priority)
- dynamic priority: between 100 (high priority) to 139 (low priority)
- real-time priority: 1 (highest priority) to 99 (lowest priority)
Kernel Preemption
In non-preemptive kernels, kernel code runs until completion. That is, the scheduler cannot reschedule a task while it is in the kernel: kernel code is scheduled cooperatively, not preemptively. Kernel code runs until it finishes (returns to user-space) or explicitly blocks.
The Linux kernel (since 2.6), unlike most other Unix variants and many other operating systems, is a fully preemptive kernel. It is possible to preempt a task at any point, so long as the kernel is in a state in which it is safe to reschedule.
Threads
Linux threads are light weight processes i.e. Linux does not make any difference between threads and processes. They share resources with parent like heap space, file descriptors, sockets but each thread gets own stack.
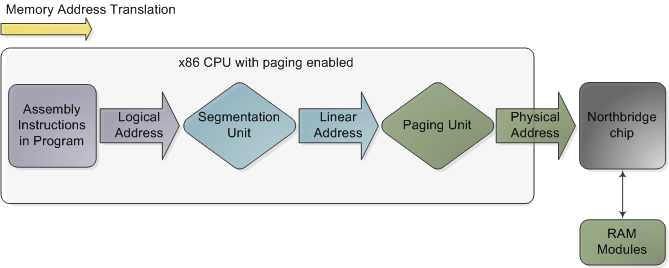
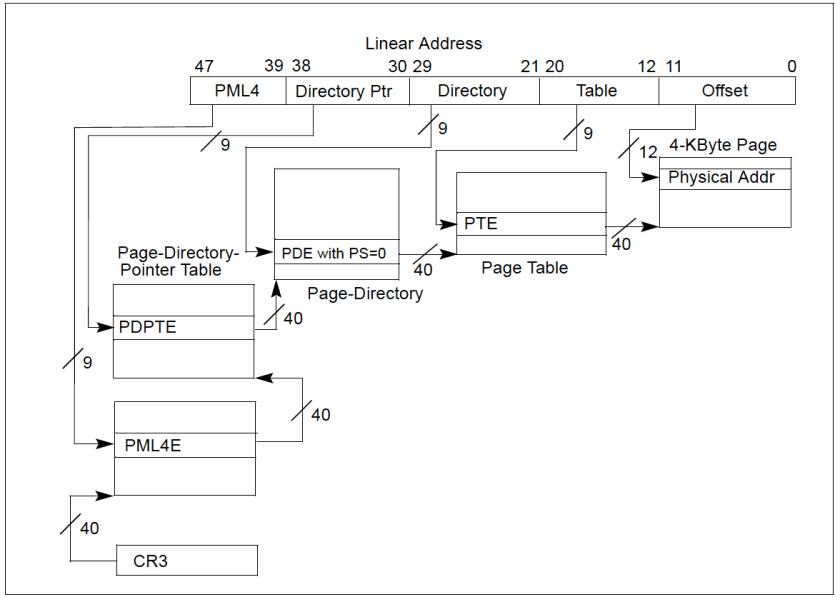
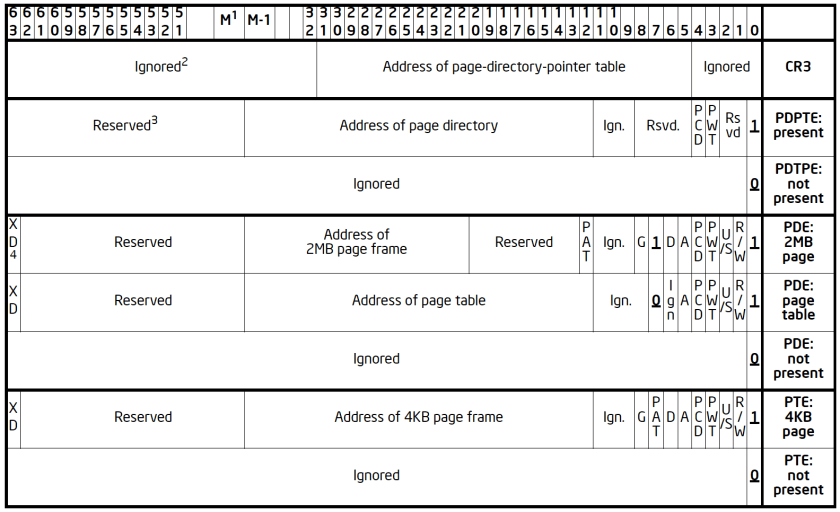
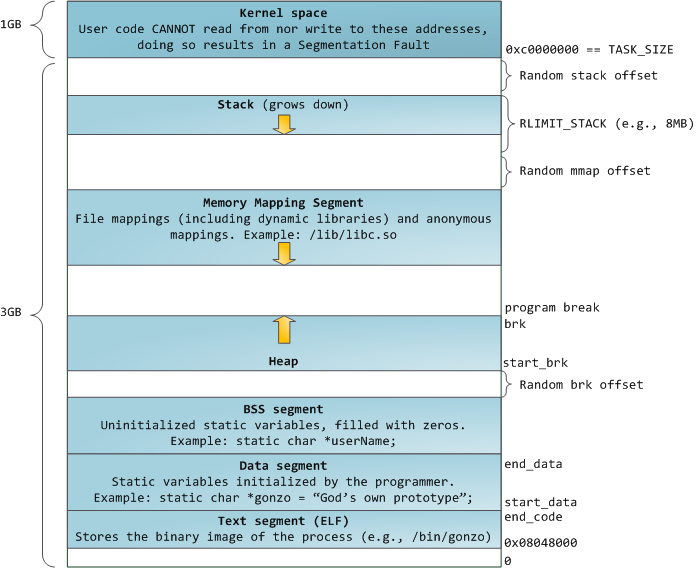
Address Space of a Process
The address space of a process consist of linear addresses the process is allowed to use. The linear address spaces are different per process. The linear addresses are managed in form of Memory Regions. Following are examples of system calls to manage memory regions:
| Syscall |
usage |
| brk()/sbrk() |
changing the heap size of process |
| execve |
Load a new program in the memory in the currently running process |
| _exit() |
exit the current process and delete the memory space occupied |
| fork() |
create a new (child) process, copying/referencing page tables from parent process |
| mmap(), mmap2() |
creates memory mapped file, enlarge the memory address space of the process. |
| mremap() |
Expand or shrink memory region |
| munmap() |
destroys previously mmaped memory area and shrinks memory space of the process |
| shmat() |
Attaches new memory region to the process |
| shmdt() |
Detaches new memory region to the process |
List all processes
Since linux uses proc file system to represent processes, listing all the processes can be done using ls /proc/
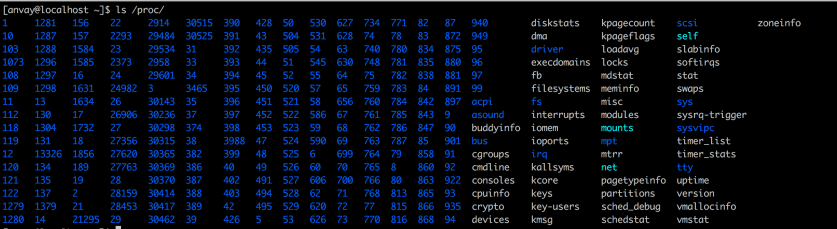
listing /proc/<PID>/

The directories and files listed here represent resources like file descriptors /fd/ etc
Memory Descriptor
The address associated with a process is stored in memory descriptor with type mm_struct. All the descriptors are stored in a doubly linked list with type mmlist.
Heap Management
malloc(size): c stdlib method to request size of Dynamic memory. On success returns pointer to first linear address. On failure returns non zero integer.
calloc(n, size):c stdlib method to request size of Dynamic memory. On success returns pointer to first linear address, set the memory to 0. On failure returns non zero integer.
realloc(size):c stdlib method that changes the size of memory location of previously allocated memory region.
free(): frees the allocated memory.
brk(address): Modifies the heap directly
sbrk(incr): increases/decreases the memory region
brk() System call:
- brk() is the only function that is a syscall. All the other functions listed above are implemented using brk() and mmap()
- it allocated and deallocated whole pages since it acts on memory region.
System calls a.k.a syscalls:
syscalls are implemented in Kernel and can be called from a process running in user space with appropriate privileges. There are around 330 number of system calls in Linux. The Linux API is written in c.
Process Termination
Process termination can be normal (finishing intended code execution) or can be abnormal. The Abnormal execution is because of following reasons:
- Kernel, the process itself or any other process send certain signal.
- Sigfault: Process tries to access memory location which it does not have privilege of access.
- Abnormal conditions is exit with non-zero code.
On process exit Kernel releases the memory and other resources held by the process like file descriptors.
When Parent process dies, the children of that process becomes orphan processes and the process init becomes parent of those processes. Sometimes parents do not wait for child processes after fork(). These child processes becomes zombi processes after termination. A process can wait (block) when its children are in the running state using wait or waitpid.
- The
wait function can block the caller until a child process terminates, whereas waitpid has an option that prevents it from blocking.
- The
waitpid function doesn’t wait for the child that terminates first; it has a number of options that control which process it waits for.