
What is Virtual Memory?
It allows us to run more applications on the system than we have enough physical memory to support. Virtual memory is simulated memory that is written to a file on the hard drive.
Why Virtual Memory?
Most of the modern CPUs has memory management unit built in to generate virtual memory addresses. Using virtual memory has following advantages.
- Main Memory is limited: especially in small devices like raspberry pi which runs linux can run multiple processes each with 32 bit addressing (4GB/process)
- Sharing: It makes easy for library programs to be shared across applications example glibc.
- Memory protection: Memory corruption in one program does not affect memory for another program.
- Only a part of program needs to be in memory execution.

Virtual Memory is implemented with
- Demand Paging
- Demand Segmentation
Physical memory management
Zones are defined using data structure struct zone, which is defined in <linux/mmzone.h>. On X86 the physical memory is divided in zones as follows
- ZONE_DMA First 16MB of memory
- This is used by (legacy) hardware because the hardware can address only upto 16 bytes.
- ZONE_NORMAL 16MiB – 896MB
- The DMA and NORMAL zone page frames can be accessed directly by Kernel.
- ZONE_HIGHMEM 896 MB – End
- In 32 bit systems – the page frames belongs to HIGHMEM can not be accessed directly by Kernel.
- In 64-bit system this problem does not exists because the linear space available is vastly large than the RAM available on the system.
Each zone has a zone descriptor with following fields:
- free_pages: Number of free pages
- pages_min: Number of reserved pages
- pages_low: Low watermark for reclaiming page frames
- pages_high: High watermark for reclaiming page frames
- free_area: Blocks of free pages
- lru_lock: spinlock for any operation
- wait_table: wait queues of processes waiting on one of the pages in the zone.
- zone_mem_map: pointer to first page descriptor
- name: “DMA”, “Normal” or “HighMem”

Zones in NUMA System

Memory Management in Linux
- Some part of main memory is assigned permanenetly to Kernel.
- Remaining memory is called as Dynamic Memory
- The effeciancy of system depends upon how effectively the memory is managed.
Page Frame sizes
- Linux uses 4 KB and 4MB page size by default.
- With PAE (Physical Address Extension) enabled it can support 2 MB pages.
- 32-bit architectures have 4KB pages
- 64-bit architectures have 8KB pages.
- This means: 4KB pages and 1GB of memory, physical memory is divided into 262,144 distinct pages.
The reason to support 4 KB page size
- Data transfer between disk and main memory is effecient when smaller page size is used.
Page Descriptors
- The page information structure is defined using
struct pagestructure. This structure is defined in<linux/mm_types.h> - Information about the state of the page frame is stored in page descriptor data structure.
- Page descriptor store following information:
- Flags
- Various flags store the information about page.
- The flag values are defined in
<linux/page-flags.h>.
- Frame’s reference counter
- This is important field. When its value is -1, the page frame free and can be accessed by any process or kernel. A 0 or positive number implies, that the page is assigned to one or more processes.
- Number of page entries
- Index
- pointer to least recently used doubly linked list
- Flags
Memory Allocation
- Zoned Page Frame Allocator is used by Kernel to handle memory allocation requests for a group of continuous page frames. The algorithm used is called as “Buddy System”. Kernel provides various macros as follows for allocating page frames.
- alloc_pages(gfp_mask, order)
- alloc_page(gfp_mask)
- _ _get_free_pages(gfp_mask, order)
- _ _get_free_page(gfp_mask)
- get_zeroed_page(gfp_mask)
- _ _get_dma_pages(gfp_mask, order)
Deallocation of page frames is done using following:
- _ _free_pages(page, order)
- free_pages(addr, order)
- _ _free_page(page)
- free_page(addr)
High-Memory Page frame mappings:
There are 3 mechanisms to map page frames in high memory:
- Permanent Kernel mapping
- Temporary Kernel Mapping
- Non Contiguous Memory Allocation
Fragmentation:
- Frequent allocations and deallocations of page frames of different sizes may result in several small blocks of free page frames scattered in the block of page frames. Then it is impossible to allocate large chunk of page frames.
- To fix this issue, Kernel keeps track of existing blocks of free contiguous page frames and avoid need to split up large blocks if request comes for smaller chunk.
Buddy System
- This is one of the algorithms for allocating memory from fixed-size segment consisting of physically-contiguous pages.
- Memory is allocated from the segment using a power-of-2 allocator
-
- This method satisfies requests in units sized as power of 2
- The requests rounded up to next highest power of 2
- When smaller allocation needed than is available, current chunk split into two buddies of next-lower power of 2
- Continue until appropriate sized chunk available
- For example, assume 256KB chunk available, kernel requests 21KB
-
- Split into AL and Ar of 128KB each
- One further divided into BL and BR of 64KB
- One further into CL and CR of 32KB each – one used to satisfy request
- One further divided into BL and BR of 64KB
- Split into AL and Ar of 128KB each
- Advantage – quickly coalesce unused chunks into larger chunk
- Disadvantage – fragmentation

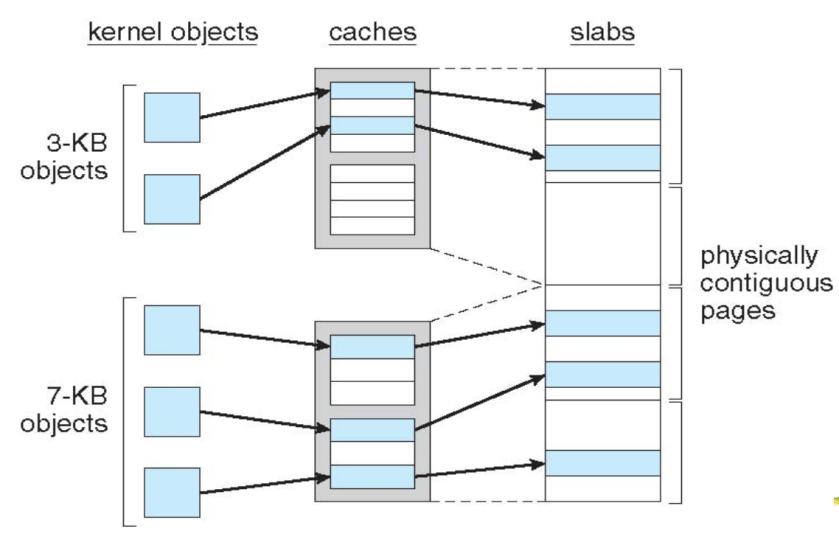
Slab Allocator
- There is an alternate strategy for Memory allocation Slab Allocator.
- A slab allocator is a list that contains a block of available, already allocated, data structures.
- When needed the data structure is allocated from the slab, when not needed, it’s returned to the slab rather than freeing.
- The slab allocator works as generic data structure caching layer.
- Slab is one or more physically contiguous pages
- Cache consists of one or more slabs
- Single cache for each unique kernel data structure
-
- Each cache filled with objects – instantiations of the kernel data structure
- Slab-allocation algorithm uses caches to store kernel objects
-
- When cache created, filled with objects marked as free
- When a new object for a kernel data structure is needed, the allocator can assign any free object from the cache to satisfy the request.
- The object assigned from the cache is marked as used.
- There are 3 states of a slab, full slab has no free objects, an empty slab has no allocated objects and partial slab has some free and some allocator objects.
- If slab is full of used objects, next object allocated from empty slab
-
- If no empty slabs, a new slab is allocated from contiguous physical pages and assigned to a cache
- Benefits include no fragmentation, fast memory request satisfaction


Demand Paging
Software Programs are generally very large in size and can not fit entirely in main memory. Hence only part of the pages are brought in main memory from disk when absolutely required.
Advantages of demand paging
- Similar to a paging system with swapping
- Less I/O needed, no unnecessary I/O
- Less memory needed. Example: Raspberry pi.
- Faster response because of shared libraries.
- More users can be using the operating system at a time
Details of demand paging
- Extreme case – start a process with no pages in memory
-
- OS sets instruction pointer to the first instruction of process, non-memory-resident page fault
- And for every other process pages on first access faults for the page
- Pure demand paging never bring a page into memory until it is required.
- Actually, a given instruction could access multiple pages multiple page faults
-
- One page for the instruction and many for data : unacceptable system performance
- Fortunately, pain decreased because of locality of reference reasonable performance
- Hardware support needed for demand paging
-
- Page table with valid / invalid bit
- Secondary memory, usually a high-speed disk. (swap device with swap space)
- Instruction restart capability after a page fault
- We must be able to restart the process in exactly the same place and state,
- With the saved state (registers, condition code, instruction counter) of the interrupted process
Stages in Demand Paging
- Trap to the operating system
- Save the user registers and process state
- Determine that the interrupt was a page fault
- Check that the page reference was legal and determine the location of the page on the disk
- Issue a read from the disk to a free frame:
- Wait in a queue for this device until the read request is serviced
- Wait for the device seek and/or latency time
- Begin the transfer of the page to a free frame
- While waiting, allocate the CPU to some other user : context switch
- Receive an interrupt from the disk I/O subsystem (I/O completed)
- Save the registers and process state for the other user
- Determine that the interrupt was from the disk
- Correct the page table and other tables to show page is now in memory: set to v
- Wait for the CPU to be allocated to this process again : context switch
- Restore the user registers, process state, and new page table, and then resume the interrupted instruction: restart
Copy on Write
- Copy-on-Write (COW) allows both parent and child processes to initially share the same pages in memory: fork() system call
-
- If either process modifies a shared page, only then is the page copied
- COW allows more efficient process creation as only modified pages are copied
- In general, free pages are allocated from a pool of zero-fill-on-demand pages
-
- Why zero-out a page before allocating it?
- vfork() as a variation on fork() system call has parent process suspended and child process uses address space of parent.
-
- Different from fork() with copy-on-write.
- Do not use copy-on-write; changes made by the child process on any pages of the parent’s address space the altered pages will be visible to the parent once it resumes
- Must be used with caution to prevent the child from modifying the parent address space
- vfork() is intended to be used when the child calls exec()immediately after creation
- No copy of pages, very efficient method of process creation.
Handling Page Fault
- Check an internal table (within PCB) to decide:
- Invalid reference ⇒ abort, terminate the process
- Valid reference ⇒ page it in when it is not in memory
- Find a free frame (taking one from the free-frame list)
- Schedule a disk operation to read the desired page into the new frame
- Reset tables to indicate the page is now in memory
- Restart the instruction that was interrupted by the trap caused by the page fault


Page Replacement Algorithms
- Find the location of the desired page on disk
- Find a free frame:
- If there is a free frame, use it
- If there is no free frame, use a page replacement algorithm to select a victim frame
- Write the victim frame to the disk if dirty
- Bring the desired page into the (newly) free frame; update the page and frame tables
- Continue the process by restarting the instruction that caused the trap
Note now potentially 2 page transfers (one out and one in) for page fault – increasing EAT
LRU Algorithm
- This is generally good algorithm and used most widely.
- Use past knowledge rather than future
- Replace page that has not been used for the longest period of time
- Associate time of last use with each page
Implementation of the LRU aalgorithm
- Need hardware assistance to determine an order for the frames defined by the time of last use.
- Counter implementation
-
- Every page entry has a time-of-use field and a logical clock (counter) is added to the CPU;
- Every time a page is referenced, the clock is incremented and the clock register value is copied into the time-of-use field in its page-table entry.
- When a page needs to be changed, look at the counters to find smallest value
- Search through table needed
- Stack implementation
-
- Keep a stack of page numbers in a doubly linked list
- When a page referenced:
- Removed from the stack and put on the top
- Most recently used page is always at the top of the stack.
- requires 6 pointers to be changed at worst
- But each update more expensive
- No search for replacement; the tail points to the bottom of the stack, the least recently used (LRU) page.
- LRU and OPT are cases of stack algorithms that don’t have Belady’s Anomaly
