
NUMA is a shared memory architecture used in today’s multiprocessing systems. Each CPU is assigned its local memory and can access memory from other CPUs in the system. Local memory access provides the best performance; it provides low latency and high bandwidth. Accessing memory that is owned by the other CPU has a performance penalty, higher latency, and lower bandwidth.
- Access to local memory is fast, more latency for remote memory
- Practically all multi-socket systems have NUMA
- Most servers have 1 NUMA node / socket
- Some AMD systems have 2 NUMA nodes / socket
- Sometimes optimal performance still requires manual tuning.
Typical 4 node NUMA system.

Image credit: https://videos.cdn.redhat.com/summit2015/presentations/15284_performance-analysis-tuning-of-red-hat-enterprise-linux.pdf
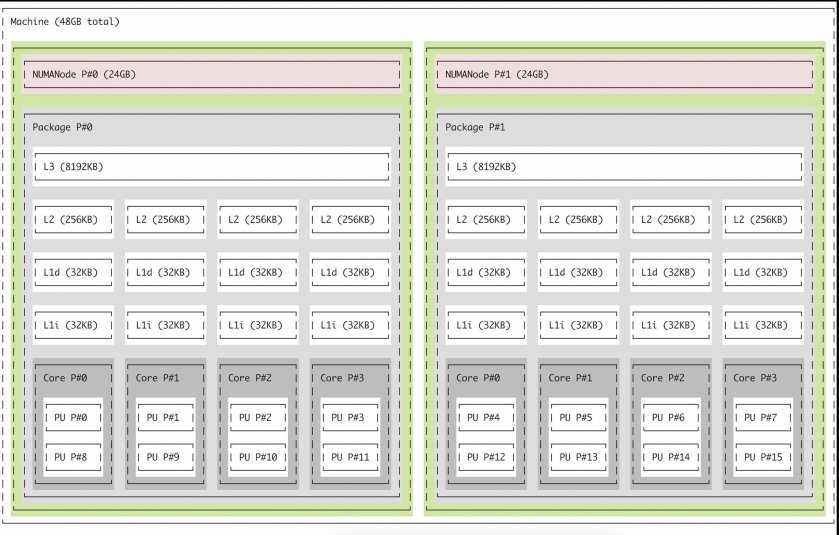
Processors and Memory layout in NUMA system

Image credit: http://pages.rubrik.com/rs/794-OHF-673/images/vSphere_6.5_Host_Resources_Deep_Dive.pdf
QPI
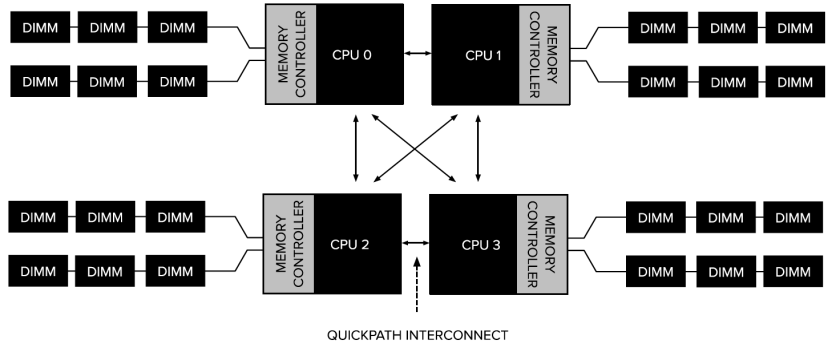
Image credit: http://pages.rubrik.com/rs/794-OHF-673/images/vSphere_6.5_Host_Resources_Deep_Dive.pdf
To see the NUMA nodes and which cpus are under numa nodes:
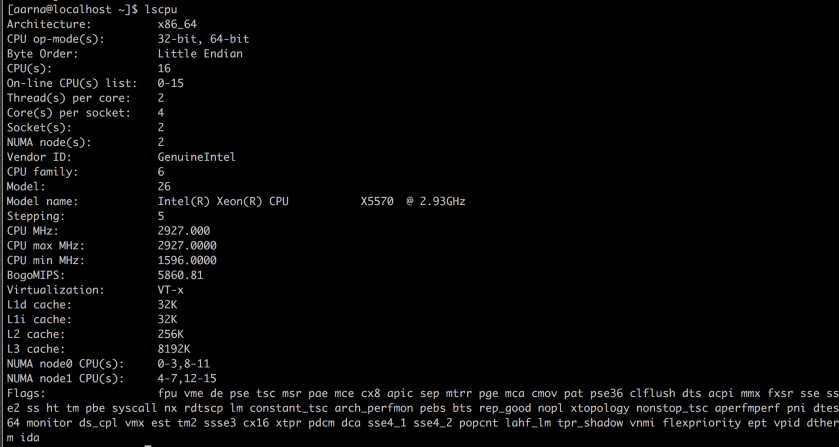
To see the CPUs under NUMA
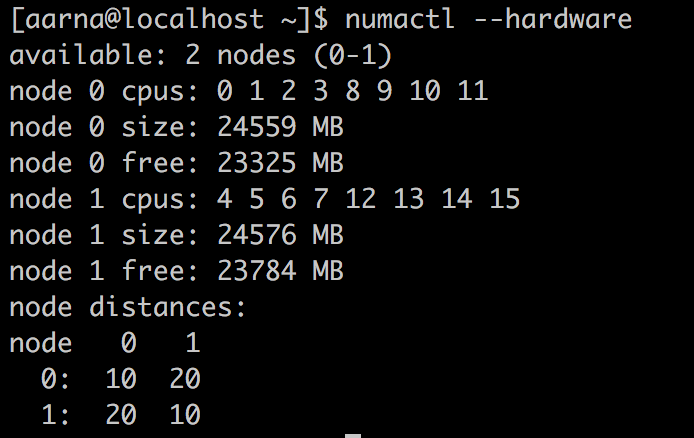
NUMA system represented on my machine.
NUMA related tools

Numa Settings
- BalancingTurn off: echo 0 > /proc/sys/kernel/numa_balancing
- NUMA locality (hit vs miss, local vs foreign)
- Number of NUMA faults & page migrations
- /proc/vmstat numa_* fields
- Location of process memory in NUMA system
- /proc/<pid>/numa_maps
- Numa scans, migrations & numa faults by node
- /proc/<pid>/sched
More info here
- https://software.intel.com/en-us/articles/a-brief-survey-of-numa-non-uniform-memory-architecture-literature
- http://pages.rubrik.com/rs/794-OHF-673/images/vSphere_6.5_Host_Resources_Deep_Dive.pdf
