
Why Synchronization
Since Linux 2.0 support Symmetric Multiprocessing with multicore modern microprocessors. But with this new dimension of problems arose like race conditions, dead/live locks etc. In order to mitigate these issues, various synchronization mechanisms were introduced in Linux. The 2.6 version of Linux supported full preemption, that means scheduler can preempt kernel code at virtually any point and reschedule another task.
- critical path: code that access and manipulate shared data
Reasons for Synchronization:
- Interrupts. An interrupt can occur asynchronously at almost any time, interrupting the currently executing code.
- Softirqs and tasklets. The kernel can raise or schedule a softirq or tasklet at almost any time, interrupting the currently executing code.
- Kernel preemption. Because the kernel is preemptive, one task in the kernel can preempt another.
- Sleeping and synchronization with user-space. A task in the kernel can sleep and thus invoke the scheduler, resulting in the running of a new process.
- Symmetrical multiprocessing. Two or more processors can execute kernel code at exactly the same time.
Ways to Synchronization
- Shared Memory
- Sockets
- Atomics and lock-free programming
- Pipes/FIFOs
- Mutexes
- recursive
- reader/writer
- Spinlocks
- Semaphores
- Binary and counting
- Condition variables
- Messages Queues
Semaphores
Since all threads run in the same address space, they all have access to the same data and variables. If two threads simultaneously attempt to update a global counter variable, it is possible for their operations to interleave in such way that the global state is not correctly modified. Although such a case may only arise only one time out of thousands, a concurrent program needs to coordinate the activities of multiple threads using something more reliable that just depending on the fact that such interference is rare.
A semaphore is somewhat like an integer variable, but is special in that its operations (increment and decrement) are guaranteed to be atomic—you cannot be halfway through incrementing the semaphore and be interrupted and waylaid by another thread trying to do the same thing. That means you can increment and decrement the semaphore from multiple threads without interference. By convention, when a semaphore is zero it is “locked” or “in use”.
Semaphores vs. mutexes (from wikipedia)
A mutex is essentially the same thing as a binary semaphore and sometimes uses the same basic implementation. The differences between them are in how they are used. While a binary semaphore may be used as a mutex, a mutex is a more specific use-case, in that only the thread that locked the mutex is supposed to unlock it. This constraint makes it possible to implement some additional features in mutexes:
- Since only the thread that locked the mutex is supposed to unlock it, a mutex may store the id of thread that locked it and verify the same thread unlocks it.
- Mutexes may provide priority inversion safety. If the mutex knows who locked it and is supposed to unlock it, it is possible to promote the priority of that thread whenever a higher-priority task starts waiting on the mutex.
- Mutexes may also provide deletion safety, where the thread holding the mutex cannot be accidentally deleted.
- Alternately, if the thread holding the mutex is deleted (perhaps due to an unrecoverable error), the mutex can be automatically released.
- A mutex may be recursive: a thread is allowed to lock it multiple times without causing a deadlock.
Semaphore is one of the thread synchronization mechanisms. Unlike mutex, semaphore allows more than one thread to access similar shared resources at the same time. There are two types of semaphores
- binary semaphore
- counting semaphore.
Pipes and FIFOs
Pipes are used for communicating data between the processes. Output of a process is piped as an input to another process.
cat doctum.txt | wc
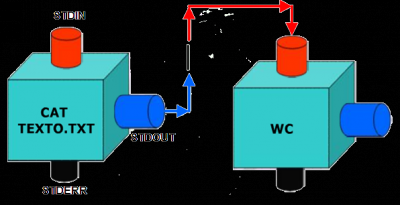
image credit: https://www.vivaolinux.com.br/dica/Pipes-no-Linux
FIFOs are named pipes. FIFOs can be used as follows:
int mkfifo(const char *path, mode_t mode); int mkfifoat(int fd, const char *path, mode_t mode);
once the FIFOs are made, they can be opened using open command and the normal file I/O functions (e.g., close, read, write, unlink) all work with FIFOs.
