
First attempt is to code the thread pool is using simple conditional variables and mutex. Once the multi-producer, multi-consumer thread pool is working as expected, its easy to convert into lock free buffer.
The Threadpool class is a struct with following member variables.
- struct Work with following member variables
- _work to store the lambda/function pointer
- _args_ary to store the array
- is_processed boolean flag.
- std::array of a fixed size to hold the work.
- static const variable to indicate the max_size of work array.
- head_idx and tail_idx to guide the next index.
- a condition variable cv
- mutex m
There are 2 main methods for enqueuing and popping the items out and working on it. Since its a circular queue, next index calculated by adding one to current index and taking remainder from max_size. i.e.
next_idx = (current_index + 1 ) % max_size
Here is an example of SPSC – single producer single consumer locked queue. The queue is bounded and blocking. Means, if either the producer or the consumer is slow, it is going to block using the condition variable and mutex.
#include <iostream>
#include <thread>
#include <array>
#include <functional>
#include <vector>
#include <random>
#include <chrono>
using func_type = std::function<int(int,int)>;
using args_ary = std::array<int,2>;
struct ThreadPool{
// Enqueue function to get the function and arguments to the function.
// consumer can invoke function with args passed on to it.
bool enqueue(func_type fn, args_ary args){
size_t next_idx = (head_idx + 1) % max_size;
std::unique_lock<std::mutex> lk(mtx);
cv.wait(lk,[&](){
return work[next_idx].processed();
});
Work w{fn, args};
work[next_idx] = w;
head_idx = next_idx;
cv.notify_all();
return true;
}
// process or pop function to pop the latest record and process it.
bool process(){
size_t next_idx = (tail_idx + 1) % max_size;
std::unique_lock<std::mutex> lk(mtx);
cv.wait(lk,[&](){
return !work[next_idx].processed();
});
Work w = work[next_idx];
work[next_idx].set_processed();
if(!w.invalid()){
int output = w.process();
std::cout << output << '\n';
}
tail_idx = next_idx;
cv.notify_all();
return true;
}
private:
struct Work{
private:
func_type _work;
args_ary _args;
bool is_processed = false;
public:
Work():is_processed(true){};
Work(func_type work, args_ary args):_work{work},_args{args},is_processed(false){};
bool processed(){
return is_processed;
}
int process(){
return _work(_args[0], _args[1]);
}
bool invalid(){
return _work == nullptr;
}
void set_processed(){
is_processed = true;
}
};
static const size_t max_size = 1000;
std::array<Work,max_size> work;
size_t head_idx = 0, tail_idx = 0;
std::condition_variable cv;
std::mutex mtx;
};
int random_num(){
std::mt19937 rng;
rng.seed(std::random_device()());
std::uniform_int_distribution<std::mt19937::result_type> dist(1,10000); // distribution in range [1,10000]
return dist(rng);
}
int main(){
ThreadPool tp;
std::thread producer1([&](){
int count = 0;
while(true){
std::function<int(int,int)> fn;
if (count % 3 == 0){
fn = [](int a, int b){ std::cout << "Adding \t\t" << a << '\t'<< b << '\t'; return a+b;};
}else if(count % 3 == 1){
fn = [](int a, int b){ std::cout << "Subtracting \t" << a << '\t'<< b << '\t'; return a-b;};
}else{
fn = [](int a, int b){std::cout << "Multiplying \t" << a << '\t'<< b << '\t'; return a*b;};
}
tp.enqueue(fn, args_ary{random_num(),random_num()});
std::this_thread::sleep_for(std::chrono::milliseconds(10));
++count;
}
});
std::thread consumer1([&](){
while(true){
tp.process();
}
});
if(producer1.joinable()){
producer1.join();
}
if(consumer1.joinable()){
consumer1.join();
}
return 0;
}
Here is a complete working example for MPMC queue.
#include <iostream>
#include <thread>
#include <array>
#include <functional>
#include <vector>
#include <random>
#include <chrono>
using func_type = std::function<int(int,int)>;
using args_ary = std::array<int,2>;
struct ThreadPool{
ThreadPool(){
for(int i = 0; i < max_size; ++i){
work[i] = Work();
}
}
bool enqueue(func_type fn, args_ary args){
size_t next_idx = (head_idx + 1) % max_size;
while(work[next_idx].processed()){
std::unique_lock<std::mutex> lk(mtx);
cv.wait(lk,[&](){
return work[next_idx].processed();
});
Work w = work[next_idx];
if(w.invalid() || w.processed()){
work[next_idx].set_work(fn);
work[next_idx].set_args(args);
work[next_idx].reset();
cv.notify_all();
break;
}
}
head_idx = next_idx;
return true;
}
bool process(int remainder, int total_threads){
size_t next_idx = (tail_idx + 1) % max_size;
std::unique_lock<std::mutex> lk(mtx);
cv.wait(lk,[&](){
return work[next_idx].unprocessed();
});
Work w = work[next_idx];
work[next_idx].set_processed();
if(!w.invalid()){
int output = w.process();
std::cout << output << '\n';
}
tail_idx = next_idx;
cv.notify_all();
return true;
}
private:
struct Work{
private:
func_type _work;
args_ary _args;
bool is_processed = false;
public:
Work():is_processed(true){};
int process(){
return _work(_args[0], _args[1]);
}
bool invalid(){
return _work == nullptr;
}
void set_processed(){
is_processed = true;
}
void set_work(func_type work){
_work = work;
}
void set_args(args_ary args){
_args = args;
}
void reset(){
is_processed = false;
}
bool unprocessed(){
return is_processed == false;
}
bool processed(){
return is_processed == true;
}
};
static const size_t max_size = 1000;
std::array<Work,max_size> work;
size_t head_idx = 0, tail_idx = 0;
std::condition_variable cv;
std::mutex mtx;
};
int random_num(){
std::mt19937 rng;
rng.seed(std::random_device()());
std::uniform_int_distribution<std::mt19937::result_type> dist(1,10000); // distribution in range [1,10000]
return dist(rng);
}
int main(){
ThreadPool tp;
auto adder = [](int a, int b){ std::cout << "Adding \t\t" << a << '\t'<< b << '\t'; return a+b;};
auto subtractor = [](int a, int b){ std::cout << "Subtracting \t" << a << '\t'<< b << '\t'; return a-b;};
auto multiplicator = [](int a, int b){std::cout << "Multiplying \t" << a << '\t'<< b << '\t'; return a*b;};
std::thread producer1([&](){
while(true){
tp.enqueue(adder, args_ary{random_num(),random_num()});
//std::this_thread::sleep_for(std::chrono::milliseconds(10));
}
});
std::thread producer2([&](){
while(true){
tp.enqueue(subtractor, args_ary{random_num(),random_num()});
//std::this_thread::sleep_for(std::chrono::milliseconds(10));
}
});
std::thread producer3([&](){
while(true){
tp.enqueue(multiplicator, args_ary{random_num(),random_num()});
//std::this_thread::sleep_for(std::chrono::milliseconds(10));
}
});
std::thread consumer1([&](){
while(true){
tp.process(0, 3);
}
});
std::thread consumer2([&](){
while(true){
tp.process(1, 3);
}
});
std::thread consumer3([&](){
while(true){
tp.process(2, 3);
}
});
if(producer1.joinable()){
producer1.join();
}
if(producer2.joinable()){
producer2.join();
}
if(producer3.joinable()){
producer3.join();
}
if(consumer1.joinable()){
consumer1.join();
}
if(consumer2.joinable()){
consumer2.join();
}
if(consumer3.joinable()){
consumer3.join();
}
return 0;
}
Output
Adding 9316 8539 17855 Subtracting 3529 1274 2255 Multiplying 7821 2404 18801684 Adding 9455 8300 17755 Subtracting 9882 5696 4186 Multiplying 202 9795 1978590 Adding 5794 7979 13773 Subtracting 4331 576 3755 Multiplying 963 4548 4379724 Adding 7238 9714 16952 Subtracting 9868 5185 4683 Multiplying 9139 4941 45155799 Adding 6842 7031 13873 Subtracting 3043 2312 731
Lockfree code
A Single producer, single consumer Lockfree queue can be written as follows
#include <iostream>
#include <thread>
#include <array>
#include <functional>
#include <vector>
#include <random>
#include <chrono>
using func_type = std::function<int(int,int)>;
using args_ary = std::array<int,2>;
struct ThreadPool{
// Constructor
ThreadPool(){
for(int i = 0; i < max_size; ++i){
work[i] = Work();
}
}
bool enqueue(func_type fn, args_ary args){
size_t current_head_idx = head_idx.load(std::memory_order_acquire);
std::atomic<size_t> next_idx = (current_head_idx + 1) % max_size;
Work w = work[next_idx];
if(w.invalid() || w.processed()){
work[next_idx].set_work(fn);
work[next_idx].set_args(args);
work[next_idx].reset();
head_idx.store(next_idx, std::memory_order_release);
}
return true;
}
bool process(){
size_t current_tail_idx = tail_idx.load(std::memory_order_acquire);
std::atomic<size_t> next_idx = (current_tail_idx + 1) % max_size;
if(!work[next_idx].processed()){
int output = work[next_idx].process();
std::cout << output << '\n';
work[next_idx].set_processed();
tail_idx.store(next_idx);
}
return true;
}
private:
struct Work{
private:
func_type _work;
args_ary _args;
bool is_processed = false;
public:
Work():is_processed(true){};
Work(func_type work, args_ary args):_work{work},_args{args},is_processed(false){};
bool processed(){
return is_processed == true;
}
int process(){
return _work(_args[0], _args[1]);
}
bool invalid(){
return _work == nullptr;
}
void set_processed(){
is_processed = true;
}
void set_work(func_type work){
_work = work;
}
void set_args(args_ary args){
_args = args;
}
void reset(){
is_processed = false;
}
};
static const size_t max_size = 1000;
std::array<Work,max_size> work;
std::atomic<size_t> head_idx{0}, tail_idx{0};
};
int random_num(){
std::mt19937 rng;
rng.seed(std::random_device()());
std::uniform_int_distribution<std::mt19937::result_type> dist(1,10000); // distribution in range [1,10000]
return dist(rng);
}
int main(){
ThreadPool tp;
std::thread producer1([&](){
int count = 0;
while(true){
std::function<int(int,int)> fn;
if (count % 3 == 0){
fn = [](int a, int b){
std::cout << "Adding \t\t" << a << '\t'<< b << '\t';
return a+b;
};
}else if(count % 3 == 1){
fn = [](int a, int b){
std::cout << "Subtracting \t" << a << '\t'<< b << '\t';
return a-b;};
}else{
fn = [](int a, int b){
std::cout << "Multiplying \t" << a << '\t'<< b << '\t';
return a*b;};
}
tp.enqueue(fn, args_ary{random_num(),random_num()});
++count;
}
});
std::thread consumer1([&](){
while(true){
tp.process();
}
});
if(producer1.joinable()){
producer1.join();
}
if(consumer1.joinable()){
consumer1.join();
}
return 0;
}
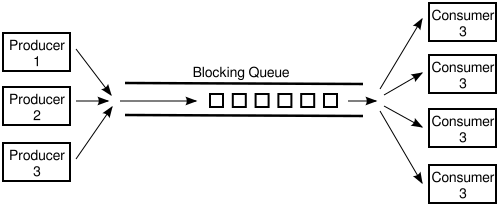



 This is a classic problem with data sharing and signaling.
This is a classic problem with data sharing and signaling. This is a classic single procedure multiple consumer problem.
This is a classic single procedure multiple consumer problem.