3 main levels for tuning
- CPU/BIOS tuning:
- Power
- P-states and C-states
- Hyper-threading
- Frequency/Turbo mode
- Governance
- Termal mode
Further reading:
https://community.mellanox.com/docs/DOC-2297
https://community.mellanox.com/docs/DOC-2817
https://www.kernel.org/doc/Documentation/cpu-freq/governors.txt
- OS tuning:
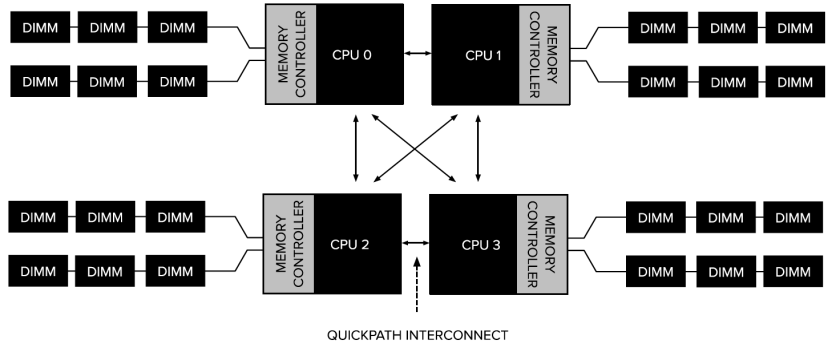
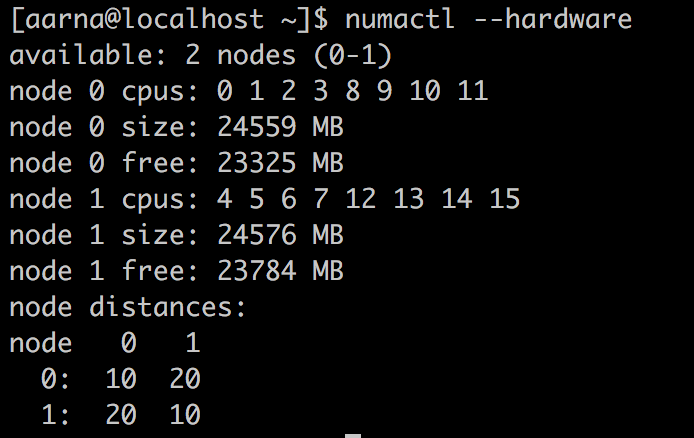
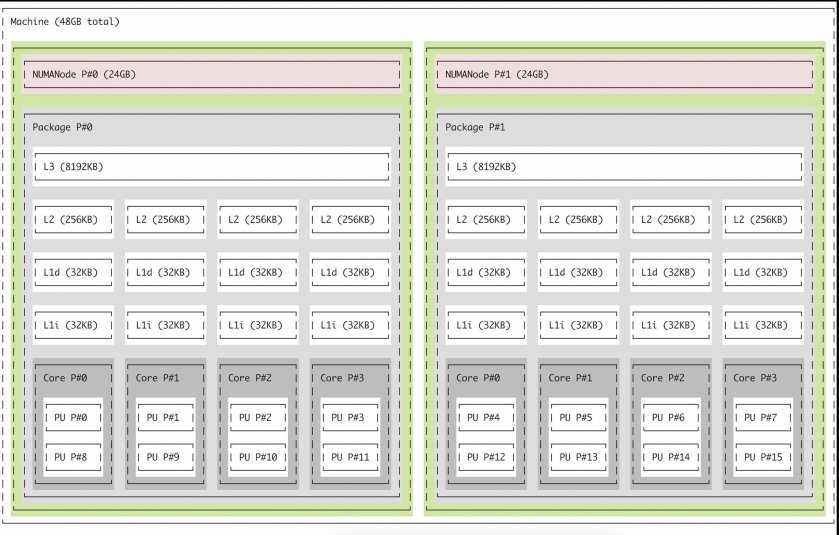
- CPU/NUMA affinity
- IRQ Affinity
- Swapiness
- Scheduling
- HUGE pages
Further Reading:
Red Hat Enterprise Linux Network Performance Tuning Guide https://access.redhat.com/documentation/en-us/red_hat_enterprise_linux/7/html/performance_tuning_guide/index https://access.redhat.com/sites/default/files/attachments/201501-perf-brief-low-latency-tuning-rhel7-v1.1.pdf
https://community.mellanox.com/docs/DOC-2135
https://community.mellanox.com/docs/DOC-2797
- Network Tuning:
- TCP/IP tunables
- Kernel Bypass Technologies
Further Reading
Kernel-bypass networking for fun and profit
https://www.youtube.com/watch?v=noqSZorzooc
Intel PDPK https://www.intel.com/content/www/us/en/communications/data-plane-development-kit.html
Fundamentals of RDMA: Free training courses on Mellanox Academy site: https://academy.mellanox.com/course/view.php?id=138
Configuration using tuned
- tuned is available from RHEL7
- Make changes in sysctl as well as /sys directory
- there are profiles available for specific needs like network-latency, latency-performance, network-performance, throughput-performance, desktop and balanced etc
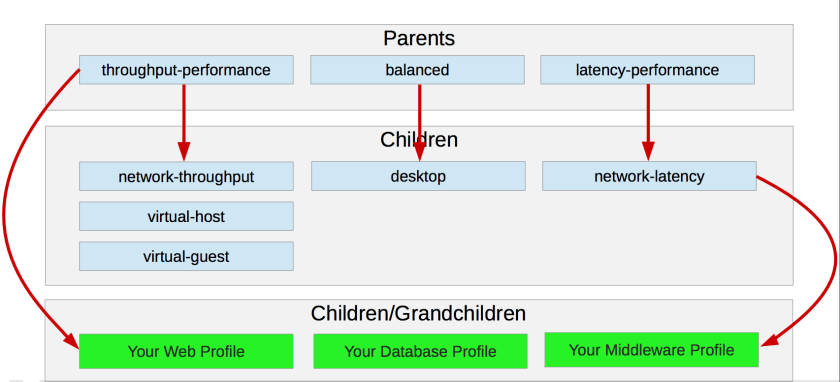
Examples of the profiles

Latency Performance Settings in Linux Tuned
| Settings | Meaning |
| force_latency=1 | processor state C1 |
| governor=performance | CPU is at higher performance state |
| energy_perf_bias= performance | Higher performance state |
| min_perf_pct=100 | comes from the P-state drivers. The interfaces provided by the cpufreq core for controlling frequency the driver provides sysfs files for controlling P state selection. These files have been added to /sys/devices/system/cpu/intel_pstate. |
| kernel.sched_min_granularity_ns=10000000 | Minimal preemption granularity for CPU-bound tasks |
| vm.dirty_ratio=10 | The generator of dirty data starts writeback at this percentage |
| vm.dirty_background_ratio=3 | Start background writeback (via writeback threads) at this percentage |
| vm.swappiness=10 | The swappiness parameter controls the tendency of the kernel to move processes out of physical memory and onto the swap disk. 0 tells the kernel to avoid swapping processes out of physical memory for as long as possible 100 tells the kernel to aggressively swap processes out of physical memory and move them to swap cache |
| kernel.sched_migration_cost_ns=5000000 | The total time the scheduler will consider a migrated process “cache hot” and thus less likely to be re-migrated |
| net.core.busy_read=50 | This parameter controls the number of microseconds to wait for packets on the device queue for socket reads. It also sets the default value of the SO_BUSY_POLL option. |
| sysctl.net.core.busy_poll=50 | This parameter controls the number of microseconds to wait for packets on the device queue for socket poll and selects |
| kernel.numa_balancing=0 | disable NUMA balancing |
| net.ipv4.tcp_fastopen=3 | Linux supports configuring both overall client and server support via /proc/sys/net/ipv4/tcp_fastopen (net.ipv4.tcp_fastopen via sysctl). The options are a bit mask, where the first bit enables or disables client support (default on), 2nd bit sets server support (default off), 3rd bit sets whether data in SYN packet is permitted without TFO cookie option. Therefore a value of 1 TFO can only be enabled on outgoing connections (client only), value 2 allows TFO only on listening sockets (server only), and value 3 enables TFO for both client and server. |
More information about Tunables:
- Dependent on NUMA:
- Reclaim Ratios
- /proc/sys/vm/swappiness
- /proc/sys/vm/min_free_kbytes
- Reclaim Ratios
- Independent of NUMA:
- Reclaim Ratios
- /proc/sys/vm/vfs_cache_pressure
- Writeback Parameters
- /proc/sys/vm/dirty_background_ratio
- /proc/sys/vm/dirty_ratio
- Readahead parameters
- /sys/block/queue/read_ahead_kb
- Reclaim Ratios
top utility
- available on all the machines
- default tool for measurement that has lot of information.
Parameters important for Optimization
Swappiness
- Controls how aggressively the system reclaims anonymous memory versus
page cache memory:- Anonymous memory – swapping and freeing
- File pages – writing if dirty and freeing
- System V shared memory – swapping and freeing
- Default is 60
- If it is decreased: more aggressive reclaiming of page cache memory
- If it is Increased: more aggressive swapping of anonymous memory
- Should be set to 0 as per the low latency optimization guide http://wiki.dreamrunner.org/public_html/Low_Latency_Programming/low-latency-programming.html
Memory reclaim watermarks:
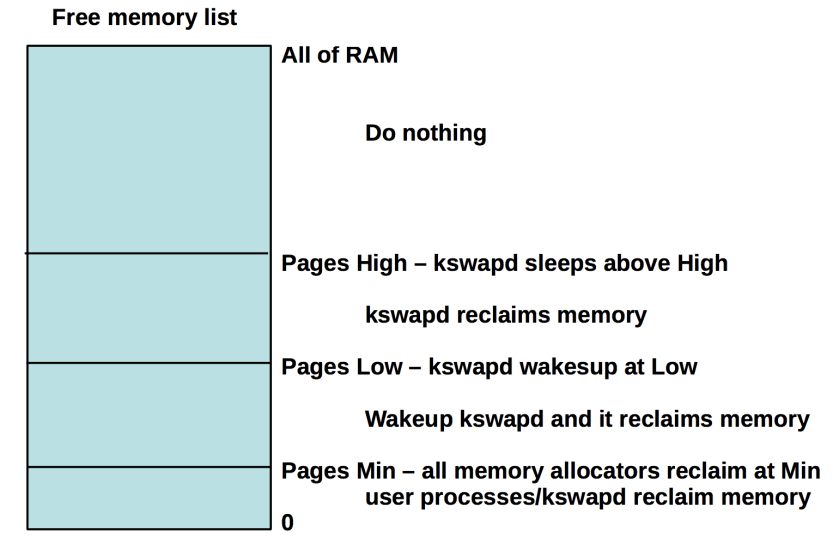
zone_reclaim_mode
- Controls NUMA specific memory allocation policy
- When set and node memory is exhausted:
- Reclaim memory from local node rather than allocating
from next node - Slower initial allocation, higher NUMA hit ratio
- Reclaim memory from local node rather than allocating
- When clear and node memory is exhausted:
- Allocate from all nodes before reclaiming memory
- Faster initial allocation, higher NUMA miss ratio
- To see current setting: cat /proc/sys/vm/zone_reclaim_mode
- Turn ON: echo 1 > /proc/sys/vm/zone_reclaim_mode
- Turn OFF: echo 0 > /proc/sys/vm/zone_reclaim_mode
- It is recommended that the settings should be off for large in memory database server.
CPU Tuning
- p-states
- It’s an Advanced Configuration and Power Interface (ACPI) defined processor performance state.
- P0, P1, P2..p11 etc are values for P-states. For highest performance the p-states should be set to P0
- c-states
-
It allow the CPU package to shut down cores and parts of the CPU microarchitecture to save energy while balancing response times.
-
C0, C1, C3, C6 etc are the values for c-states. Here is the chart for more information
Mode Name What it does CPUs C0 Operating State CPU fully turned on All CPUs C1 Halt Stops CPU main internal clocks via software; bus interface unit and APIC are kept running at full speed. 486DX4 and above C1E Enhanced Halt Stops CPU main internal clocks via software and reduces CPU voltage; bus interface unit and APIC are kept running at full speed. All socket LGA775 CPUs C1E — Stops all CPU internal clocks. Turion 64, 65-nm Athlon X2 and Phenom CPUs C2 Stop Grant Stops CPU main internal clocks via hardware; bus interface unit and APIC are kept running at full speed. 486DX4 and above C2 Stop Clock Stops CPU internal and external clocks via hardware Only 486DX4, Pentium, Pentium MMX, K5, K6, K6-2, K6-III C2E Extended Stop Grant Stops CPU main internal clocks via hardware and reduces CPU voltage; bus interface unit and APIC are kept running at full speed. Core 2 Duo and above (Intel only) C3 Sleep Stops all CPU internal clocks Pentium II, Athlon and above, but not on Core 2 Duo E4000 and E6000 C3 Deep Sleep Stops all CPU internal and external clocks Pentium II and above, but not on Core 2 Duo E4000 and E6000; Turion 64 C3 AltVID Stops all CPU internal clocks and reduces CPU voltage AMD Turion 64 C4 Deeper Sleep Reduces CPU voltage Pentium M and above, but not on Core 2 Duo E4000 and E6000 series; AMD Turion 64 C4E/C5 Enhanced Deeper Sleep Reduces CPU voltage even more and turns off the memory cache Core Solo, Core Duo and 45-nm mobile Core 2 Duo only C6 Deep Power Down Reduces the CPU internal voltage to any value, including 0 V 45-nm mobile Core 2 Duo only - Latency for C states
C-STATE
RESIDENCY
WAKE-UP LATENCY
C0
ACTIVE
ACTIVE
C1
1 μs
1 μs
C3
106 μs
80 μs
C6
345 μs
104 μs
-
How to Optimize
- Use real production system for measurement
- Note the state of system before change
- Apply the optimizations later going to come in the post.
- Compare state of system after applying the optimizations
- Tune until you get desired results.
- Document the changes.
Types of Tools needed
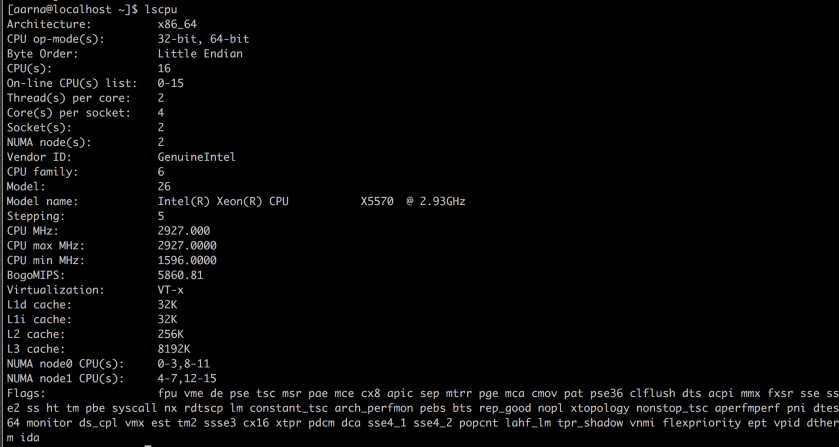
- Tools that gather system information or Hardware
- lscpu
- uname
- systemctl list -units -t service
- Tools for measuring Performance
- Tools for Microbenchmarking
Optimization include Benchmarking, Profiling and Tracing
- Benchmarking
- this is comparing performance with industry standard
- Tools used for benchmarking
- vmstat used for benchmarking virtual memory
- iostat used for benchmarking io
- mpstat multiple processor
- Profiling gathering information about hot spots
- Tracing
Based on the Benchmarking, Profiling and Tracking the system is tuned as follows;
- using echo into /proc
- The settings are not persistent. Stay until reboot.
- /proc files system has pid directories for processes, configuration files and sys directory
- /proc/sys directory has some important directories like /kernel, /net, /vm , /user etc.
- /proc/sys/vm has settings for with virtual memory.
- Using sysctl command
- sysctl it’s a service
- Persistent settings.
- It’s started at the boot time’s
- It reads settings from a configuration file at /etc directory
- There are some more settings in
- usr/lib/sysctl.d stores the default
- /run/sysctl.d stores the runtime
- /etc/sysctl.d stores runtime settings
- Using loading/unloading of kernel modules and configure kernel parameters
- Using modinfo to gather information about available parameters
- Using modprobe for modifying parameters
- modprobe modulename key=val
- for persistent settings, /etc/modprobe.d modulename.conf