Because the CPU and/or the compiler can reorder the instructions written in program order. Modern processors and Compilers try to optimize the program by reordering the instructions all the time. But the observed effects (on load and stores on memory locations) are consistent.
Sequential Consistency
is defined as the result of any execution is the same as if the read and write operations by all processes were executed in some sequential order and the operations of each individual process appear in this sequence in the order specified by its program [Lamport, 1979].
which means:
The instructions executed by the same CPU in order as they were written.
all the threads should observe the effect of loads/stores to any shared variable.
Sequential consistency is very important especially in multi-threaded programs because when a thread changes the shared variable, the other threads should see the variable in a consistent and valid state.
Total Store Ordering
Modern processors have a buffer where they store the updates to the memory location called as store buffer. The reason, updates do not go to main memory directly is writes to main memory are very slow and value from store buffer can be reused because of spatial locality.
Architectures with Strong Store Ordering guarantees: x86, SPARC
Architectures with weak Store Ordering guarantees: ARM, POWER, alpha etc.
Types of Barriers:
Compiler Barriers
This is to prevent compiler from reordering the instructions.
in Modern c++ (c++ 11) following compiler barriers are introduced:
A barrier can be applied by calling std::atomic_thread_fence() with argument for memory orders as memory_order_relaxed, memory_order_consume, memory_order_acquire, memory_order_release, memory_order_acq_rel, memory_order_seq_cst etc.
Mandatory Barriers (Hardware)
Example instructions are mfence, lfence or sfence.
The modern microprocessor pipeline is 14 stages deep during which the programming instructions reordered all the times for optimization purposes.
Linux 2.6 supports full preemption, i.e. the thread can be suspended in between.
Atomic types are the locations in main memory to which the access is exclusive to a thread/process.
Barriers are used for ordering the accesses to the memory locations.
Atomic operations are provided at hardware level in order to make the operations indivisible.
The Implementation is highly dependent upon the hardware. x86 has strictest rules around memory ordering.
Atomic operations with memory fences prevents reordering of the instructions in order to make theoperation indivisible.
Atomic operations are expensive because the OS and hardware can not do all the necessary optimizations.
<atomic> header provides various atomic types. Following is non-exhaustive list of atomic types
atomic_bool
std::atomic<bool>
atomic_char
std::atomic<char>
atomic_schar
std::atomic<signed char>
atomic_uchar
std::atomic<unsigned char>
atomic_int
std::atomic<int>
atomic_uint
std::atomic<unsigned>
atomic_short
std::atomic<short>
atomic_ushort
std::atomic<unsigned short>
atomic_long
std::atomic<long>
atomic_ulong
std::atomic<unsigned long>
atomic_llong
std::atomic<long long>
atomic_ullong
std::atomic<unsigned long long>
atomic_char16_t
std::atomic<char16_t>
atomic_char32_t
std::atomic<char32_t>
atomic_wchar_t
std::atomic<wchar_t>
Operations on Atomic types
These operations take a argument for memory order. Which can be one of std::memory_order_relaxed, std::memory_order_acquire, std::memory_order_release, std::memory_order_acq_rel, std::memory_order_consume or std::memory_order_seq_cst
load: this is read operation on an atomic type.
store: this is a write operation on an atomic type.
exchange: this is read-modify-write operation on an atomic type. All the compare operations are used as compare_exchange(expected, desired, <optional memory order>). On successful exchange it return true else it returns false.
compare_exchange
compare_exchange_weak: these are really for the architectures where the read-modify-write operation is not guaranteed atomic. It can generate spurious errors and it is advised to use in a loop. It has same effect as of compare_exchange_strong on x86 platform.
compare_exchange_strong: it is guaranteed to return false on failure and guaranteed to return true on success.
fetch_ versions of add, or etc
overriden operators like +=, -=, *=, |=
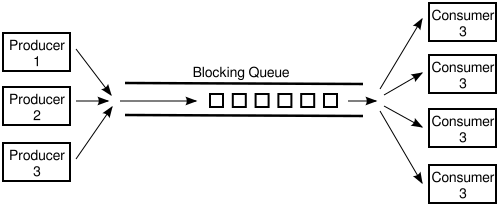
Lock Based implementation of a Multi-producer, Multi-consumer Queue.
It is important to see the lock based data structures before implementing lock-free data structures.
/*
Code for Lock based queue.
std::queue is wrapped in a struct Queue.
internal_queue variable maintains the queue.
Work to do is an instance of struct Work.
Queue has pop and push functions.
Push function takes the work instance by rvalue instance and
pushes it onto the internal queue.
Pop function returns a shared pointer to Work. The shared pointer
is used to avoid the ABA problem.
Pop function is a non blocking function.
If the queue is empty, the thread just yields.
A sleep is added in order to simulate slowness in the work..
Disadvantages of this kind of queue:
* Whole Queue is locked during any operations in order to make
sure there is synchronized access.
*/
#include <queue> // std::queue
#include <mutex> // for locking
#include <thread>
#include <memory> // smart pointers
#include <utility>
#include <functional> // passing and storing lambda
#include <iostream> // for std::cout
#include <chrono>
static long work_number = 0;
struct Work{
// take lambda as a work and call lambda to process.
Work(std::function<void(void)> lambda):f(lambda){};
void operator()(){
f();
}
private:
std::function<void(void)> f;
};
struct Queue{
Queue() = default;
// Queue is not copyable or copy constructible.
Queue(const Queue &) = delete;
Queue & operator=(const Queue &) = delete;
std::shared_ptr<Work> pop();
void push(Work &&);
private:
std::mutex mtx;
std::queue<Work> internal_queue;
};
void Queue::push(Work && work){
std::lock_guard<std::mutex> lg(mtx);
internal_queue.push(work);
}
std::shared_ptr<Work> Queue::pop(){
Work w([](){});
{
std::lock_guard<std::mutex> lg(mtx);
if(internal_queue.size() > 0){
w = std::move(internal_queue.front());
internal_queue.pop();
}
else
{
std::this_thread::yield(); // let the other threads work
}
}
return std::make_shared<Work>(w);
}
struct Producer{
Producer(Queue & q):q(q){};
void produce(){
for(;;){
Work w([&](){std::cout << "work number : " << ++work_number << " is called.." << "\n";});
q.push(std::move(w));
}
}
private:
Queue & q;
};
struct Consumer{
Consumer(Queue & q):q(q){};
void consume(){
for(;;){
std::shared_ptr<Work> w_ptr = q.pop();
Work * w = w_ptr.get();
(*w)();
std::this_thread::sleep_for(std::chrono::milliseconds(100));
}
}
private:
Queue & q;
};
int main(){
Queue q;
std::thread producer_thread1([&q](){
Producer p(q);
p.produce();
});
std::thread producer_thread2([&q](){
Producer p(q);
p.produce();
});
std::thread consumer_thread1([&q](){
Consumer c(q);
c.consume();
});
std::thread consumer_thread2([&q](){
Consumer c(q);
c.consume();
});
std::thread consumer_thread3([&q](){
Consumer c(q);
c.consume();
});
producer_thread1.join();
producer_thread2.join();
consumer_thread1.join();
consumer_thread2.join();
consumer_thread3.join();
return 0;
}
Lock Free Data Structures
In the above implementation, the data structure is a lock based one and hence no two threads can access is concurrently.
Simple example of defining work as () operator overload on a struct.
#include <thread>
#include <iostream>
struct work{
void operator ()() const{
std::cout << "this is test from work" << std::endl;
}
};
int main(){
work w;
std::thread t([&](){
w();
});
t.join(); // wait in the main thread for finishing the thread t.
return 0;
}
std::thread objects are not copyable but they are movable.
std::thread t1([]{std::cout << std::this_thread::get_id() << std::endl;});
std::thread t2 = t1; // NOT going to work since constructor
for thread class is private
std::thread t2 = std::move(t1); // this work!
Detach thread: background/long running jobs which does not to report the status back to parent threads can be detached.
#include <thread>
#include <iostream>
#include <vector>
#include <atomic>
std::atomic<int> total(0);
int main(){
std::vector<std::thread> workers;
for(int i = 0; i <= 20; ++i){
workers.emplace_back(
std::thread([](){
for(int j = 0; j <= 20; ++j){
// can also use ++total same effect
// Memory order does not matter on x86
total.fetch_add(1, std::memory_order_relaxed);
}
}));
}
std::for_each(
workers.begin(),
workers.end(),
[](auto & w){
if(w.joinable()){
w.join();
}
}
);
std::cout << total << std::endl;
return 0;
}
Using non-atomic variables with mutexes to prevent data races
#include <mutex>
#include <thread>
#include <iostream>
#include <vector>
static int total = 0;
static int worker_count = 20;
std::mutex mtx;
int main(){
std::vector<std::thread> workers;
workers.reserve(worker_count);
for(int i = 0; i < worker_count; ++i){
workers.emplace_back(std::thread([](){
for(int j = 0; j < worker_count; ++j){
std::lock_guard<std::mutex> lkg(mtx);
++total;
}
})
);
}
for(auto & worker: workers){
if (worker.joinable()){
worker.join();
}
}
std::cout << total << std::endl;
return 0;
}
DCLP – Double Checked Linked Pattern
As per the paper by Scott Meyers and Andrei Alexandrescu, the DCLP pattern implementation is given below.
In order to get instance of a singleton class, there are two checks, first check without the lock, then the lock is acquired and then again checked if the instance exists.
Singleton* Singleton::instance() {
if (pInstance == 0) { // 1st test
Lock lock; // acquire the lock
if (pInstance == 0) { // 2nd test
pInstance = new Singleton;
}
}
return pInstance;
}
In order to simplify this situation, c++ standard came with call_once and once_flag.
std::once_flag pInstance_initialized; // Flag
std::call_once(pInstance_initialized, {pInstance =new Singleton;});
Here is an example code called once as per the once flag:
#include <thread>
#include <iostream>
#include <vector>
#include <chrono>
#include <atomic>
int worker_count = 20;
int main(){
std::vector<std::thread> workers;
workers.reserve(worker_count);
std::once_flag is_called;
workers.reserve(worker_count);
for(int i = 0; i < worker_count; ++i){
workers.emplace_back(std::thread([&](){
std::call_once(is_called, [](){
std::cout << "once_flag is set in the thread id " << std::this_thread::get_id() << std::endl;
});
})
);
}
for(auto & worker: workers){
if (worker.joinable()){
worker.join();
}
}
return 0;
}
Condition Variables: used for intercommunication between the threads. Condition Variables work with mutex as a way of synchronization between threads.
Following is a classic example of printing number series like 0102030405… using 3 threads. One thread prints 0, another prints all odd numbers and 3rd thread prints even numbers. Condition variables are used to solve this problem.
This is a classic problem with data sharing and signaling.
Five (male) philosophers spend their lives thinking and eating. The philosophers share a common circular table surrounded by five chairs, each belonging to one philosopher. In the centre of the table there is a bowl of spaghetti, and the table is laid with five forks, as shown in figure. When a philosopher thinks, he does not interact with other philosophers. From time to time, a philosopher gets hungry. In order to eat he must try to pick up the two forks that are closest (and are shared with his left and right neighbors), but may only pick up one fork at a time. He cannot pick up a fork already held by a neighbor. When a hungry philosopher has both his forks at the same time, he eats without releasing them, and when he has finished eating, he puts down both forks and starts thinking again.
Solutions to this kind of problem are as follows:
Use resource hierarchy: assign numbers to the forks (resources). The philosopher can only request resource with lower number first then the higher number.
Use a central entity for assigning permissions: use a arbitrator (waiter) as a mutex which will allow the philosopher to periodically use the forks(resources).
Distributed message passing between the philosophers without a central authority.
For every pair of philosophers contending for a resource, create a fork and give it to the philosopher with the lower ID (n for agent Pn). Each fork can either be dirtyor clean. Initially, all forks are dirty.
When a philosopher wants to use a set of resources (i.e. eat), said philosopher must obtain the forks from their contending neighbors. For all such forks the philosopher does not have, they send a request message.
When a philosopher with a fork receives a request message, they keep the fork if it is clean, but give it up when it is dirty. If the philosopher sends the fork over, they clean the fork before doing so.
After a philosopher is done eating, all their forks become dirty. If another philosopher had previously requested one of the forks, the philosopher that has just finished eating cleans the fork and sends it.
Sleeping Barber Problem
This is a classic single procedure multiple consumer problem.
The analogy is based upon a hypothetical barber shop with one barber. The barber has one barber chair and a waiting room with a number of chairs in it. When the barber finishes cutting a customer’s hair, they dismiss the customer and go to the waiting room to see if there are other customers waiting. If there are, they bring one of them back to the chair and cut their hair. If there are no other customers waiting, they return to their chair and sleep in it.
Each customer, when they arrive, looks to see what the barber is doing. If the barber is sleeping, the customer wakes them up and sits in the chair. If the barber is cutting hair, the customer goes to the waiting room. If there is a free chair in the waiting room, the customer sits in it and waits their turn. If there is no free chair, the customer leaves.


 This is a classic problem with data sharing and signaling.
This is a classic problem with data sharing and signaling. This is a classic single procedure multiple consumer problem.
This is a classic single procedure multiple consumer problem.